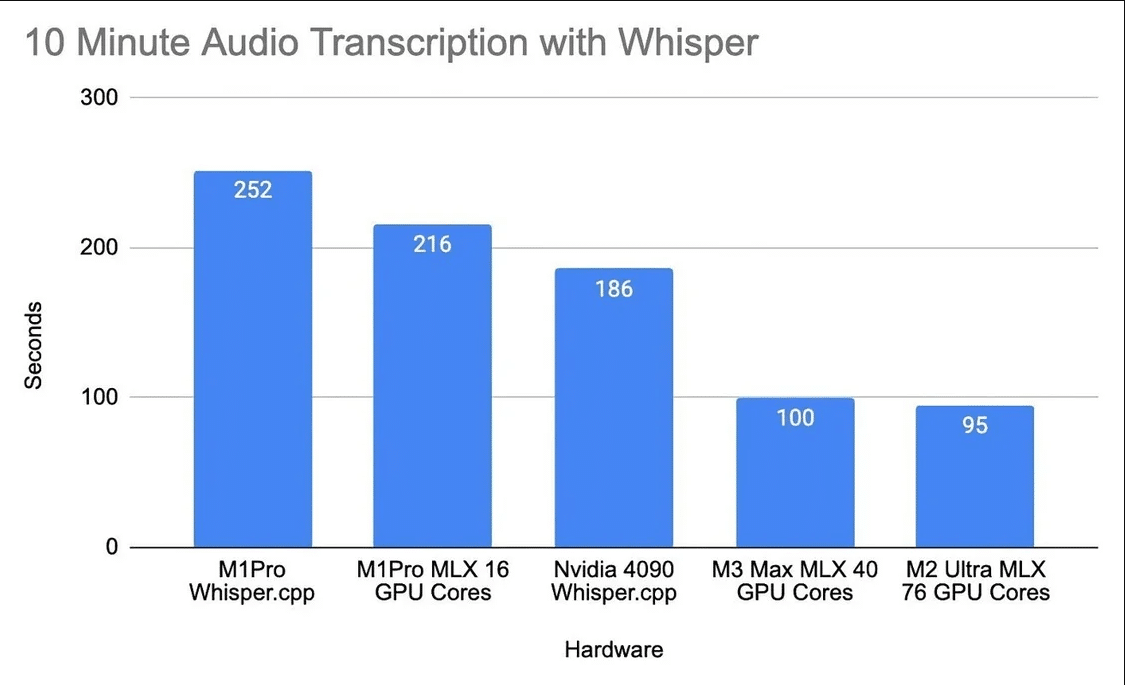
Test results reveal that Apple M1 Pro, M2 Ultra, and M3 Max chips exhibit impressive audio processing capabilities. Specifically, trials employing OpenAI’s Whisper speech recognition model demonstrate that the M1 Pro processes audio in just 216 seconds, surpassing the Nvidia RTX 4090 graphics card, which requires 186 seconds for the same task. Notably, despite the M2 Ultra having 76 GPUs and the M3 Max featuring 40 GPUs, both outperform the RTX 4090. Apple M2 Ultra only takes 95 seconds to complete, and Apple M3 Max takes 100 seconds to complete.
Furthermore, in terms of power consumption, Apple’s Apple Silicon chips excel. In a comparative analysis, the NVIDIA RTX 4090 consumes an additional 242W in running mode compared to idle mode, while devices equipped with the M1 Pro chip only exhibit a 38W increase from idle to running mode.
It is important to highlight that Apple adopted the “MLX” framework during the development of the deep learning framework. This framework boasts several features, including Python and C++ APIs, ease of learning, efficient performance optimization, delayed calculation for improved resource efficiency, and seamless integration of software and hardware. Leveraging the CPU and GPU of Apple devices, “MLX” effectively offers superior hardware support, capitalizing on unified memory to accelerate data movement.
Tailored for researchers, this framework empowers them to harness Apple devices for enhanced deep-learning research capabilities. Apple’s Apple Silicon chip excels in audio processing and power efficiency, while the “MLX” framework enhances user convenience and facilitates optimized deep learning research on Apple devices.
The MLX framework incorporates the following attributes:
- Recognizable Interfaces: Python and C++ interfaces incorporate well-known frameworks like NumPy and PyTorch, providing a smooth learning curve for seasoned researchers.
- Streamlined and Effective: MLX employs modular feature transformations to optimize performance on Apple Silicon.
- Deferred Calculation: Capability to avert unnecessary computations, enhancing resource efficiency.
- Adaptive Architecture: Capable of adjusting to changes in input shape, streamlining the debugging and testing procedures.
- Integration of Hardware and Software: MLX seamlessly harnesses the CPU and GPU of Apple devices, ensuring users maximize their hardware capabilities.
- Unified Memory Benefits: MLX leverages Apple’s unified memory for accelerated data movement.
- Researcher-Centric: MLX is tailored with researchers in mind.
Read Also: Asus ROG Zephyrus 16 (2024) Exposed: Ultra 9 185H and RTX 4090
