

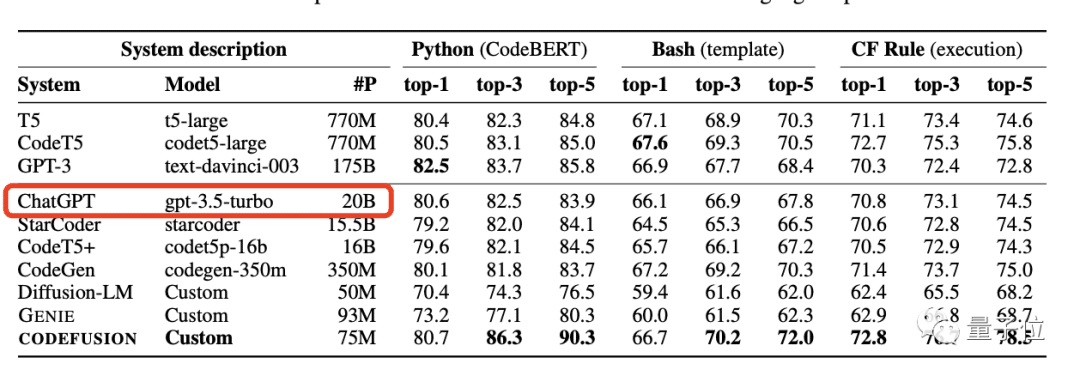
Microsoft’s research department has published a paper on the pre-trained code generation model Microsoft CodeFusion. In comparing baseline data for code generation tasks, an interesting discovery was made – ChatGPT (get-3.5-turbo) has only 20 billion parameters.

Moreover, it’s worth noting that not-3.5-turbo is one of the most widely used and mature models at OpenAI. Its predecessor, GPT-3.5, was revealed to have 1.75 trillion parameters. Such a small parameter count proves to be more powerful in performance and efficiency while being more cost-effective.

This also indirectly validates what Meta asserted when they first open-sourced Llama earlier this year – smaller parameter models can perform just as well as high-parameter models when trained on extensive, high-quality datasets.

Many well-known open-source large model projects both nationally and internationally. It such as Baichuan Large Models, LLaMA-2, and Falcon-40B, have outperformed higher-parameter models in multiple benchmark tests while consuming fewer resources.
To continue, let’s delve into the innovative code model, CodeFusion, released by Microsoft


Products like GitHub Copilot and Chat have already validated the feasibility and significant role of large language models in the field of programming. They can quickly generate various types of code based on text descriptions, greatly enhancing development efficiency.
However, the generated code often faces challenges like errors and poor quality. To address this pain point, Microsoft has introduced the innovative code model, CodeFusion. What sets CodeFusion apart from traditional code models is the introduction of a “diffusion process” pattern. It gradually adds noise to the code, transitioning from simplicity to complexity, and then gradually reduces the noise to return to a clean state.

Inspired by Midjourney and other diffusion models, researchers have designed a unique “denoising” mechanism. It enables the model to automatically learn code syntax and generate more accurate, high-quality code.
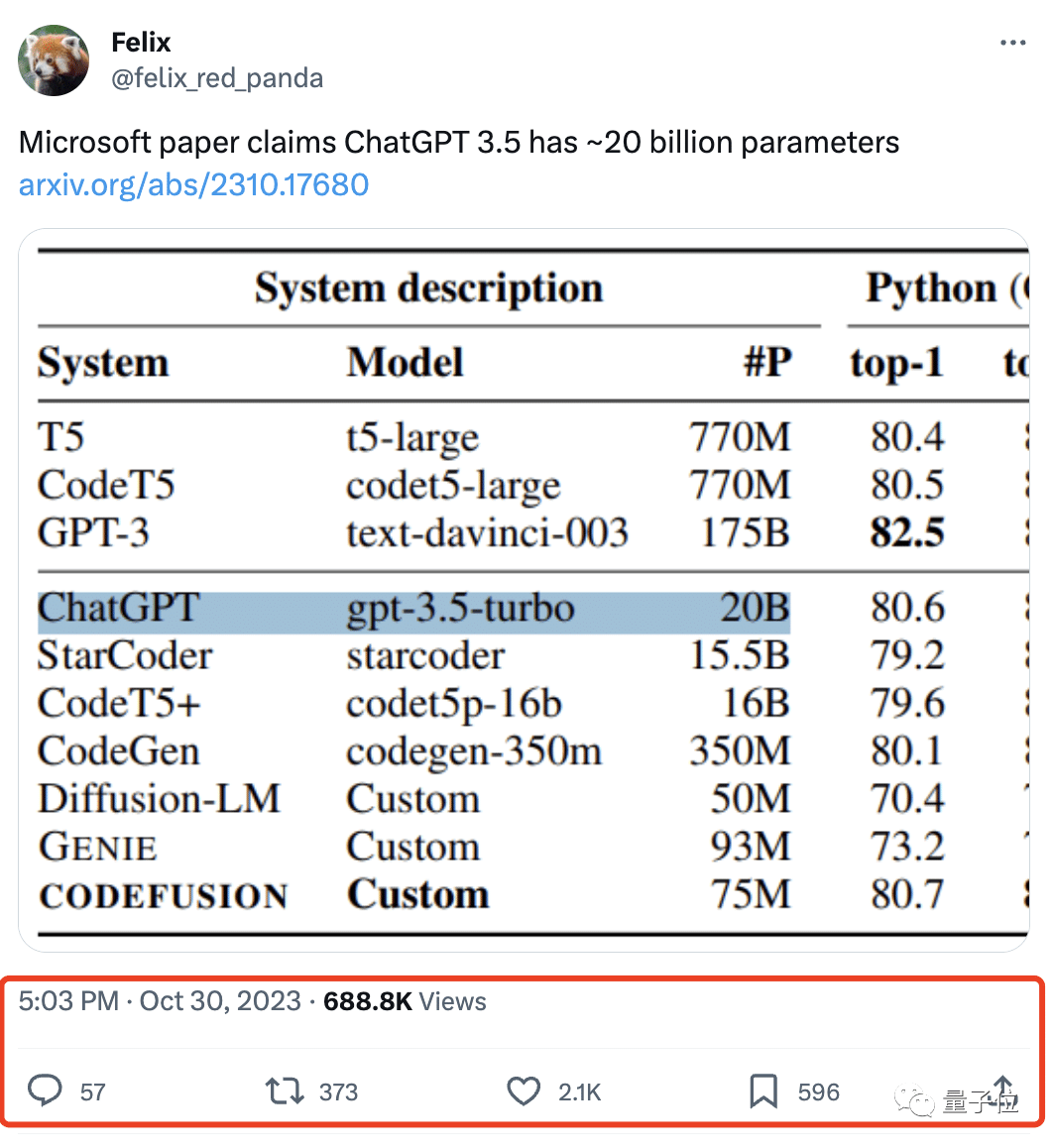

To evaluate the effectiveness of CodeFusion, the research team conducted comparisons across various programming languages, including Python, Bash, and Excel formulas. When compared to mainstream code generation models like T5, CodeT5, GPT-3, and CodeGen, CodeFusion achieved remarkable results. Whether in terms of single-shot code generation accuracy or the probability of generating correct code after multiple attempts, CodeFusion displayed a clear advantage.
In Python, CodeFusion achieved a single-shot accuracy of 80.7%, surpassing GPT-3. Considering the top 5 generations, CodeFusion had a 90.3% probability of containing correct code, while other models reached a maximum of only 85.8%. Similarly, in Bash and Excel languages, CodeFusion demonstrated strong performance.
In code diversity tests, CodeFusion’s top 5 candidate code generations achieved a code line coverage of 81%, which is twice as high as other models.

It’s worth mentioning that CodeFusion has only 75 million parameters, significantly fewer than the models in the test with tens of billions or even hundreds of billions of parameters. This once again confirms that smaller parameter models can outperform high-parameter models, as mentioned earlier.
CodeFusion Evaluation Data
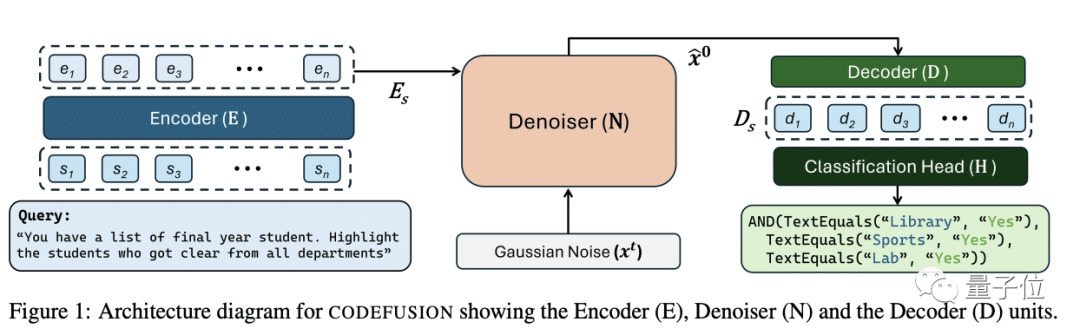
From the paper’s description, the architecture of Microsoft CodeFusion primarily consists of three main modules: Encoder, Denoiser, and Decoder.
The Encoder’s role is to convert natural language input into vector representations. It first tokenizes the input text and then passes it through a pre-trained transformer encoder, such as T5’s encoder, mapping each word to a dense word vector.
The transformer encoder employs several layers of self-attention and feed-forward networks to grasp contextual semantic details from the input text. This process yields a final semantic vector representation. Key technical points include:
-
Using pre-trained models captures semantic information without starting from scratch.
-
Creating a global semantic vector: By employing self-attention, we capture the overall context and meaning of the input text. It enables words from different positions to collectively shape a comprehensive semantic representation.
- Efficient encoding: Compared to sequential models like RNNs, transformer encoders can perform highly parallelized computations and effectively model long texts.
The Denoiser’s function is to introduce a diffusion process by adding Gaussian noise to the encoder’s output. The denoiser first initializes a noise vector, and based on the diffusion steps. I blend the encoder’s output semantic vector with the noise vector through weighted averaging, resulting in a hidden state vector with added noise.


As the iteration steps increase, the proportion of incorporated noise gradually grows. It causes the state vector to progressively deviate from the original semantics, introducing more randomness. This simulates a physical diffusion process. The output of the denoiser is a sequence of states with increasingly enhanced noise complexity. This provides a target function from simple to complex for the decoding stage, making it easier for the model to optimize.
The Decoder’s goal is to recover the source text’s meaning from noisy states and produce precise code. The decoder uses a transformer structure, taking the denoiser’s state output in each step. It applies self-attention with the source semantic vector to understand the state’s internal meaning. It cross-attention to grasp its connection to source semantics. And must predict how much noise to remove from the current state to obtain the clean state from the previous step. This process continues until the source semantic vector is fully restored.
Finally, the decoder achieves the mapping from diffusion hidden states to source semantics and then to code symbols. It enables the transformation from natural language prompts to code. This article is based on material from the Microsoft CodeFusion paper. If there are any copyright concerns, please contact us for removal.
Read Also: Microsoft’s Redesigned Xbox Series X: New Features and Immersive Controller Revealed